
On stage at the aiPulse conference at StationF in Paris last week, Gradium CEO Neil Zeghidour placed a small robot on the floor at the foot of the stage. The Reachy Mini, a compact, expressive machine borrowed from Hugging Face, had been connected to the voice AI API developed by Gradium.
After a quick command from Zeghidour, Reachy blinked to life and began speaking in a warm, natural voice. Over the next few minutes, it transformed from a cheerful assistant into a boisterous gym coach named Logan, then pivoted seamlessly into Quebec-accented French to discuss the philosophy of human-machine communication.
The audience watched as the robot's personality, voice, and language shifted on command, guided by nothing more than conversational prompts, eventually breaking into a little dance upon request.
"This was completely unscripted," Zeghidour said afterward, grinning.
Video courtesy of Scaleway
The demonstration was a glimpse of the future that Zeghidour and his co-founders are racing to build. In this world, voice becomes the primary interface between humans and machines, as natural and intuitive as conversation between two people.
Just days earlier, Zeghidour's company had emerged from three months of stealth mode with a €60 million seed round and a roster of backers that spans Silicon Valley royalty, French industrial titans, and some of the world's most respected AI researchers. Gradium's ambitions are as outsized as its funding.
"The potential of voice AI is not realized to even 1% of what it can be," Zeghidour told the audience. "Voice is going to be the way we interact with machines."
From Open Research to Commercial Reality
Gradium represents an unusual model in the European AI ecosystem: a commercial spinout from Kyutai, the nonprofit research lab founded in 2023 with backing from French billionaire Xavier Niel, shipping magnate Rodolphe Saadé, and former Google CEO Eric Schmidt.
At Kyutai, Zeghidour and his co-founders developed Moshi, a groundbreaking open-source conversational AI that demonstrated real-time, natural voice interactions, and Hibiki, the first real-time speech-to-speech translation system.
These research prototypes generated enormous interest from enterprises eager to deploy them. But there was a problem: research prototypes aren't products.
"There is a last mile between what is a good research prototype and what is an actual product," Zeghidour explained at aiPulse. The models were English-only, lacked studio-quality audio, and weren't robust enough for production environments. "Pushing the limits of the latency, the quality, so that we can finally reach voice AI in products that feel natural, robust, fun, engaging, that's the job of a company, because it's not only about making scientific breakthroughs, but really pushing the level of details to the finest precision."
The founding team Zeghidour has assembled to tackle this challenge reads like a who's who of audio AI. Laurent Mazaré, the Chief Coding Officer, previously worked at Google DeepMind and quantitative trading firm Jane Street. Olivier Teboul, the CTO, comes from Google Brain. Alexandre Défossez, the Chief Scientist, was a senior researcher at Meta. Together, they bring more than a decade of experience developing audio foundation models.

Building the Voice Layer for AI
Rather than targeting specific applications, Gradium is positioning itself as infrastructure, the foundational layer that enables other companies to build voice-enabled products.
"Our positioning is that we are not making products for a specific vertical," Zeghidour said. "We make the building blocks that are used by a lot of businesses to create voice agents and voice experience."
The company's initial product suite focuses on real-time transcription and synthesis, enabling developers to create what Zeghidour calls "customizable voice agents." The key differentiator, he argues, is that users can modify both the personality and voice of any agent as easily as they might adjust a text-based chatbot.
This flexibility has already attracted an eclectic mix of early customers. Video game developers are using the technology to power NPCs and generate real-time esports commentary. Healthcare companies are deploying it for medical transcription and voice restoration for patients with neurodegenerative diseases. Media groups are creating personalized content that adapts to individual listener preferences. Customer service operations are building more natural-sounding voice agents.
"Hundreds of thousands of phone calls are powered by our models," Zeghidour said, a striking number for a company that officially launched just three months after incorporation.
A Rare Coalition of Backers

The €60 million seed round, co-led by FirstMark Capital and Eurazeo, has attracted an unusually diverse group of investors spanning Silicon Valley, European tech, and French industry.
Of course, Schmidt, Niel, and Saadé joined the round. The roster also includes DST Global Partners, Korelya Capital, and Amplify Partners. The strategic investors reflect the breadth of potential applications: from telecommunications to logistics to consumer technology.
Perhaps more telling is the participation of prominent AI researchers and operators, including Yann LeCun, Meta's chief AI scientist and a Turing Award winner; Thomas Wolf, co-founder of Hugging Face; and Olivier Pomel, co-founder of Datadog. Their involvement suggests that those closest to the technology see genuine differentiation in Gradium's approach.
The Technical Moat

What sets Gradium apart in an increasingly crowded voice AI market? Zeghidour points to the team's comprehensive understanding of the entire audio stack.
"If you look at the market for people who make voice models, it's actually pretty small," he said. "And interestingly, people are either typically specialized in making synthesis or making transcription. What we have learned along the years, and developed in particular at Kyutai, is audio foundation models where we completely master the full stack of audio, from transcribing, translating, synthesizing, improving audio, and transforming audio."
The platform currently supports English, French, German, Spanish, and Portuguese, with additional languages in development.
Despite the impressive launch, Zeghidour is candid about the challenges that remain. Current voice AI systems, including Gradium's, still fall short on emotional intelligence.
"Emotional understanding from AI is still pretty poor," he acknowledged. "We heard feedback from a company that does AI therapy. People use the product, and then they start opening up about personal problems. Maybe they're going to say, 'My dog has passed away,' and the AI is like, 'Oh, that's pretty sad.' This is just so inappropriate. Having AI that understands the emotional context, that reacts in a way a human will do—I think this is a big frontier."
Robotics represents another major opportunity and challenge. As robots move into factories, homes, and public spaces, they'll need to understand speech in conditions far more complex than a quiet conference room.
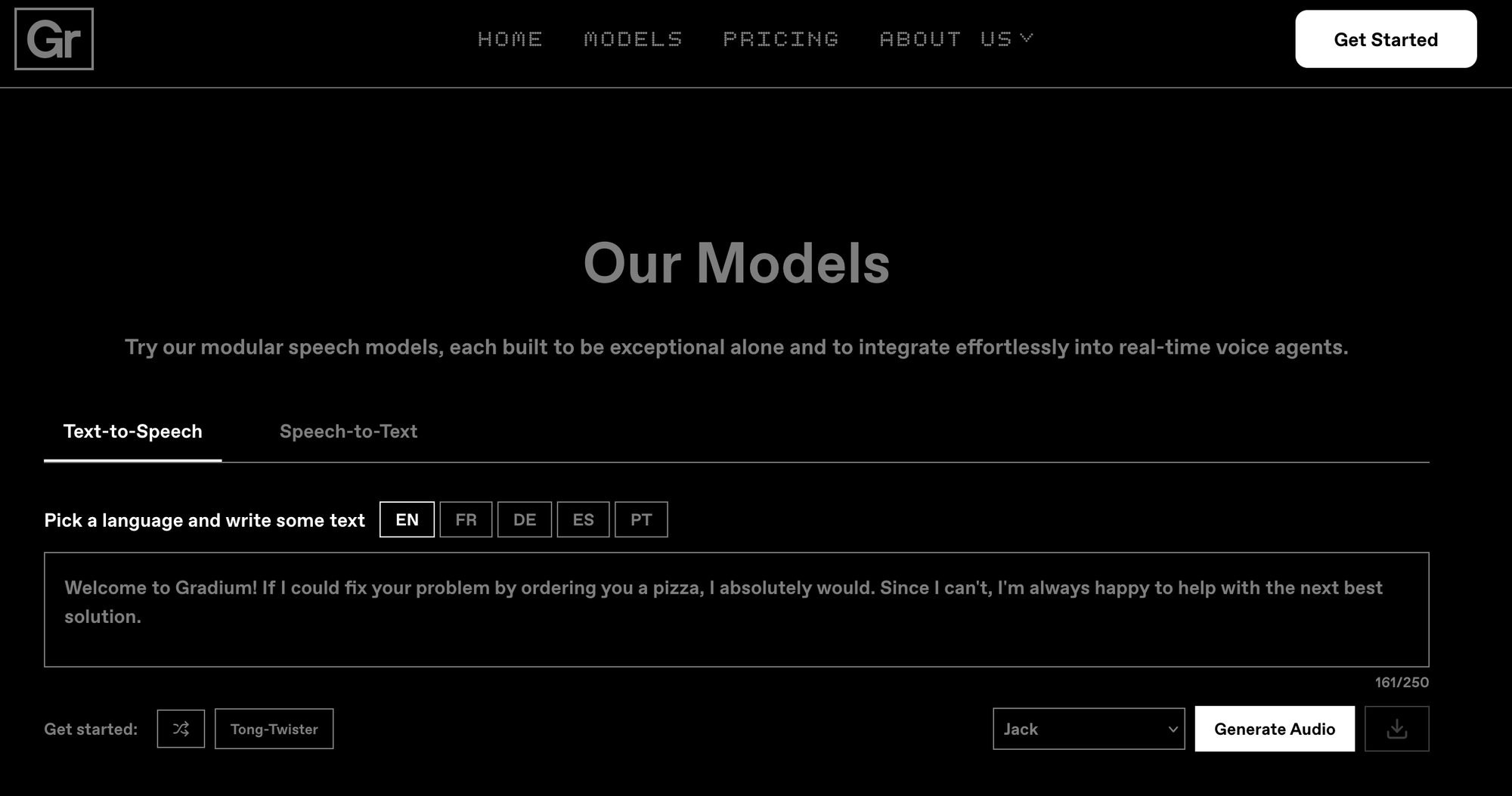
"Imagine that you have a robot in a factory that needs to interact with a lot of people who shout from various distances, with machinery noise and so on," Zeghidour said. "This is completely out of the picture today. Nobody can build such a thing."
Gradium is already working on these problems alongside Kyutai, maintaining a long-term research collaboration with the nonprofit lab. It's a model Zeghidour hopes can be replicated: fundamental research driving commercial innovation, which in turn funds further basic research.
Zeghidour said: "We are on a path to become the world leader for voice AI, and that's our ambition, and that's our objective."






{kind=link}